


Over the past nine years, HelloGitHub has amassed a treasure trove of over 3,000 open-source projects. Yet, as our collection grows, we’ve been hearing from users that the search function isn’t cutting it. They tell us, “We can’t find the projects we’re looking for!” This feedback hit home, and I realized that simply listing projects isn’t enough. We need to enable our users to discover the open-source projects that truly spark their interest in a smarter way. That’s why I began to think about how to solve this problem using RAG technology.
Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model (LLM) by retrieving relevant information from an external knowledge base before generating a response.
I’ve been intrigued by RAG for a while, but I was unsure where to start. While there are plenty of user-friendly RAG low-code tools out there, I didn’t want to just scratch the surface of “how to use it.” I craved a deeper understanding of its inner workings, or else I wouldn’t feel confident deploying it in a production environment. However, the idea of building a RAG system from scratch using LangChain and Ollama does give me some pause.
It was not until recently that I happened to notice that OceanBase is making some progress. In version 4.3.3, they’ve introduced support for vector type storage, vector indexes, and embedding vector retrieval, which is a game-changer. What’s particularly impressive is that they’ve crafted a hands-on tutorial tailored for beginners like myself who are eager to explore RAG. It guides users step-by-step on how to build a RAG chatbot using Python, making the technology accessible and easy to grasp.
OceanBase GitHub: github.com/oceanbase/oceanbase
Talking about it just isn’t going to cut it, so I figured it’s time to roll up my sleeves and dive right in. Let’s see what this is all about!
Next up, I’m excited to walk you through building a chatbot for the HelloGitHub open-source community using this project. I’ll be covering the nitty-gritty of the implementation process, diving into detailed optimizations, and sharing my insights and future outlook on RAG technology.
1 How does the RAG chatbot work?
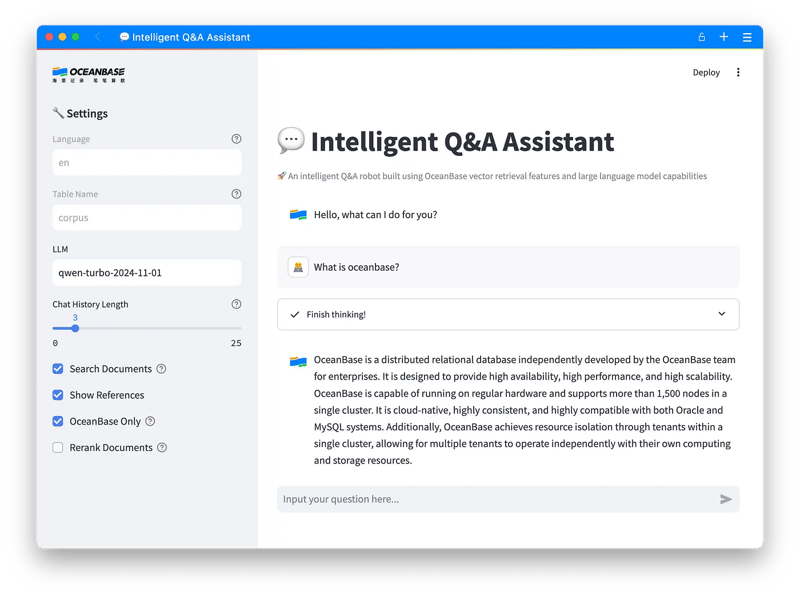
OceanBase’s open-source RAG chatbot is a handy tool for navigating through OceanBase documentations. It’s designed to deliver spot-on answers to users’ document-related queries through a natural language conversation flow. No more sifting through endless pages — just ask, and it delivers.
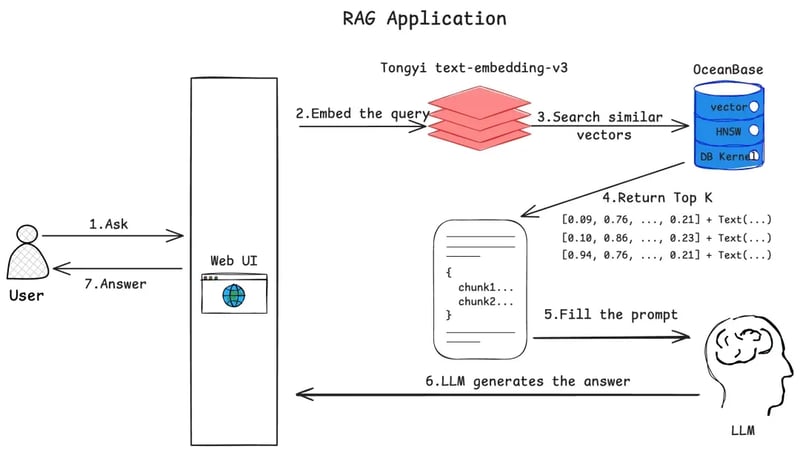
The project is built on langchain, langchain-oceanbase, and streamlit.
Here’s the scoop: it starts by turning OceanBase database documents into vector data with an Embedding model, which are then stored in the OceanBase database. When a question pops up, the system converts it into a vector using the same model. It then fetches related document content via vector retrieval and feeds these documents as context to the large language model, all to craft more spot-on responses.
I gave it a try, and the results were pretty impressive. That got my gears turning: what if I replaced the OceanBase documents with the Markdown files of HelloGitHub Monthly and integrated them into the system? It could morph into a chatbot made just for HelloGitHub. So, without further ado, I’m off to give it a shot!
2 Installation and Execution
Before diving into the developing work, you’ll need to get the project up and running. The installation and execution steps are well-documented in the practical tutorials provided by OceanBase, so I’ll keep it brief. Here’s how you can get the project rolling:
- Vectorize Your Docs: Run the
embed_docs.pyscript to turn your documents into vectorized data and store it in OceanBase. - Fire Up the Project: Launch the project with the command
streamlit run --server.runOnSave false chat_ui.py.
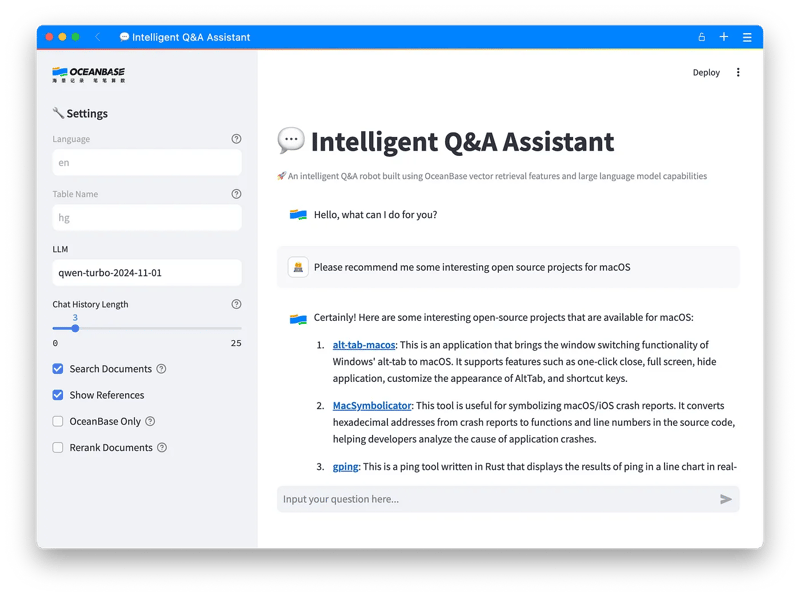
Once it’s up and running, you’ll be redirected to the interface below:
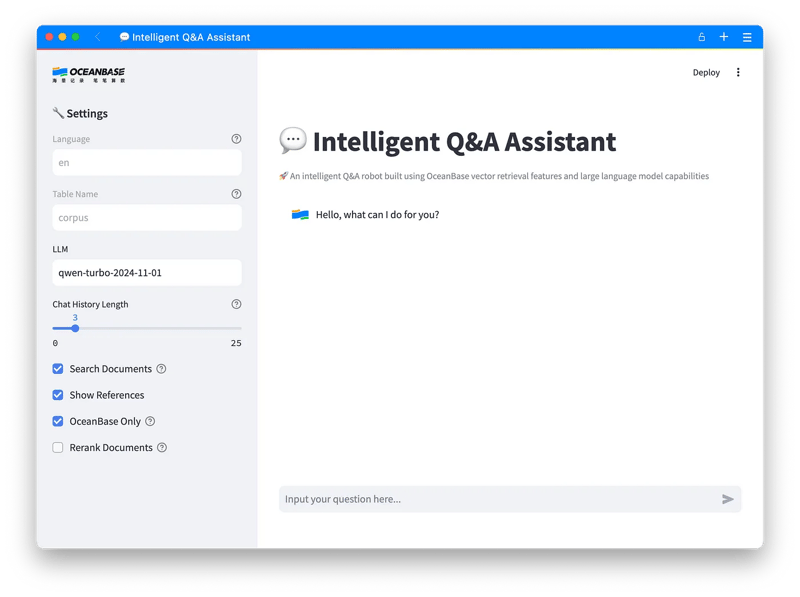
Suggestions:
- Python Version Management: The project needs Python 3.9 or higher to run smoothly. I’d suggest usingpyenv to manage your Python version—it’s a lifesaver for keeping your project environments tidy.
- Database Viewing: Whether you’re deploying OceanBase via Docker or using OceanBase Dedicated (the Cloud version of OceanBase), a GUI tool for local database viewing can be a real asset. It’s super handy for development and debugging, making it easier to keep an eye on what’s happening under the hood.
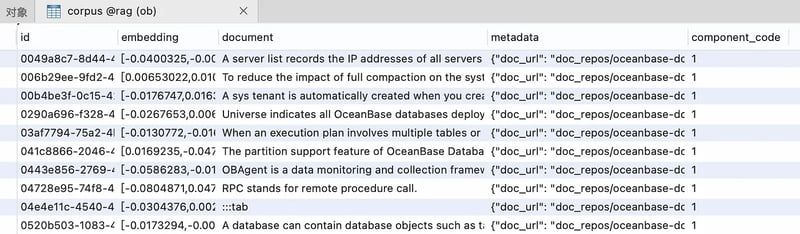
After you’ve run the embed_docs.py script and taken a peek at the database tables, you’ll spot a few key fields:
-
document: This is where the original document content hangs out. -
embedding: Here, you’ll find the vectorized data from the documents. -
metadata: It keeps track of handy info like the document’s name, path, and segmented titles.
The embedding column is particularly interesting—it’s packed with array-like data. This is the output of the Embedding model, which transforms documents into vectors. These vectors are like the secret sauce for capturing the text’s semantic essence, allowing the computer to really get what the text is about. This sets the stage for cool features like semantic search (calculating distances), making it easier to match questions with the right document content in later steps.
3 Start Transformation
This project not only supports LLMs API but also can be switched to use the local Ollama API. This adjustment can be easily made by modifying the .env configuration file.
# Using Models with Embed API SupportOLLAMA_URL=localhost:11434/api/embedOLLAMA_TOKEN=OLLAMA_MODEL=all-minilm# Using Models with Embed API Support OLLAMA_URL=localhost:11434/api/embed OLLAMA_TOKEN= OLLAMA_MODEL=all-minilm# Using Models with Embed API Support OLLAMA_URL=localhost:11434/api/embed OLLAMA_TOKEN= OLLAMA_MODEL=all-minilm
Enter fullscreen mode Exit fullscreen mode
Tips: When using third-party paid APIs, keep an eye on those usage limits. It’s wise to import just a chunk of documents for testing or debugging with your local LLM to dodge any unwanted costs.
3.1 Importing HelloGitHub Monthly
To vectorize and import the content of HelloGitHub Monthly into the OceanBase database using the embed_docs.py script, use the following command:
python embed_docs.py --doc_base /HelloGitHub/content --table_name hgpython embed_docs.py --doc_base /HelloGitHub/content --table_name hgpython embed_docs.py --doc_base /HelloGitHub/content --table_name hg
Enter fullscreen mode Exit fullscreen mode
Parameter Description:
-
doc_base: Directory of HelloGitHub content. -
table_name: The script will automatically create this table and store the data right in there.
But, after giving the script a spin, I noticed that the document field in the database was a bit of a mess. It was filled with a bunch of irrelevant stuff like formatting symbols and other random info:
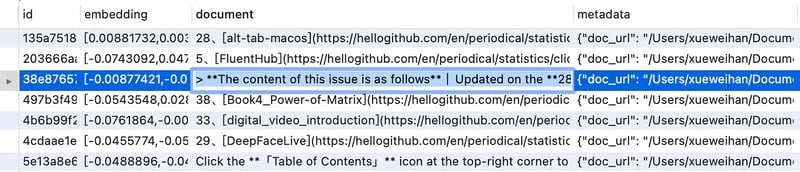
Dealing with that noisy data, I whipped up a script to clean up those pesky formatting symbols and extra fluff, and then gave them a fresh import into the database.

3.2 Running the Project
To get the service up and running, you’ll need to set the TABLE_NAME environment variable to point to the table you want to use. Here’s the command to do that:
TABLE_NAME=hg2 streamlit run --server.runOnSave false chat_ui.pyTABLE_NAME=hg2 streamlit run --server.runOnSave false chat_ui.pyTABLE_NAME=hg2 streamlit run --server.runOnSave false chat_ui.py
Enter fullscreen mode Exit fullscreen mode
I took it for a spin, but the response performance wasn’t quite hitting the mark:
After putting it through its paces, I dug into the potential reasons behind its lackluster performance. Here’s what I came up with:
- Vectorization Effect: The all-minilm model we’re using has just 384 dimensions. Maybe it’s time to give a larger Embedding model a shot.
- Data Cleaning: I’ve cleaned up some of the irrelevant stuff, but there could still be some noisy data lurking around that needs more thorough processing.
- Document Completeness: We need to dig deeper to see if HelloGitHub’s content structure is a good fit for the question-answering model.
- Prompt Words: The design of prompt words needs some fine-tuning, and adding more context might help things along.
4 Optimizing Question-Answering Effectiveness
I’m starting to feel a connection to RAG, so I’m planning to switch to the paid but more effective Tongyi Qianwen text-embedding-v3 model (1024 dimensions) for debugging.
4.1 Data Optimization
To really boost the question-answering game, I’m diving deeper into optimizing how the documents are built. The plan is to import tables from the HelloGitHub website into the OceanBase database. By leveraging this data, I can craft cleaner and more precise content. This not only ensures we have comprehensive project data but also cuts down on irrelevant noise, making vector retrieval more on point.
Importing Tables into OceanBase
Since OceanBase is highly compatible with MySQL, I migrated the table structure and content from MySQL to OceanBase using Navicat. Then, I wrote an embed_sql.py script to retrieve data directly from the relevant tables and generate more streamlined content (document), while also adding metadata and storing it all in the database. Here’s the core code:
<span># Create document </span><span>content</span> <span>=</span> <span>f</span><span>"""</span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>'</span><span>name</span><span>'</span><span>,</span> <span>'</span><span>None</span><span>'</span><span>)</span><span>}</span><span>: </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>'</span><span>title_en</span><span>'</span><span>,</span> <span>'</span><span>None</span><span>'</span><span>)</span><span>}</span><span>. </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>'</span><span>summary_en</span><span>'</span><span>,</span> <span>'</span><span>None</span><span>'</span><span>)</span><span>}</span><span>"""</span><span># Init metadata </span><span>metadata</span> <span>=</span> <span>{</span><span>"</span><span>repository_name</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span><span>"</span><span>repository_url</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>url</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span><span>"</span><span>description</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>summary_en</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span><span>"</span><span>category_name</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>category_name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span><span>"</span><span>language</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>primary_lang</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span><span>"</span><span>chunk_title</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span><span>"</span><span>enhanced_title</span><span>"</span><span>:</span> <span>f</span><span>'</span><span>content -> </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>category_name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>)</span><span>}</span><span> -> </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>)</span><span>}</span><span>'</span><span>...</span><span>}</span><span># Adding content and metadata to a document object </span><span>docs</span><span>.</span><span>append</span><span>(</span><span>Document</span><span>(</span><span>page_content</span><span>=</span><span>content</span><span>.</span><span>strip</span><span>(),</span> <span>metadata</span><span>=</span><span>metadata</span><span>))</span><span># Store in database </span><span>vs</span><span>.</span><span>add_documents</span><span>(</span><span>docs</span><span>,</span><span>ids</span><span>=</span><span>[</span><span>str</span><span>(</span><span>uuid</span><span>.</span><span>uuid4</span><span>())</span> <span>for</span> <span>_</span> <span>in</span> <span>range</span><span>(</span><span>len</span><span>(</span><span>docs</span><span>))],</span><span>)</span><span># Create document </span><span>content</span> <span>=</span> <span>f</span><span>"""</span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>'</span><span>name</span><span>'</span><span>,</span> <span>'</span><span>None</span><span>'</span><span>)</span><span>}</span><span>: </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>'</span><span>title_en</span><span>'</span><span>,</span> <span>'</span><span>None</span><span>'</span><span>)</span><span>}</span><span>. </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>'</span><span>summary_en</span><span>'</span><span>,</span> <span>'</span><span>None</span><span>'</span><span>)</span><span>}</span><span>"""</span> <span># Init metadata </span><span>metadata</span> <span>=</span> <span>{</span> <span>"</span><span>repository_name</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span> <span>"</span><span>repository_url</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>url</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span> <span>"</span><span>description</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>summary_en</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span> <span>"</span><span>category_name</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>category_name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span> <span>"</span><span>language</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>primary_lang</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span> <span>"</span><span>chunk_title</span><span>"</span><span>:</span> <span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>),</span> <span>"</span><span>enhanced_title</span><span>"</span><span>:</span> <span>f</span><span>'</span><span>content -> </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>category_name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>)</span><span>}</span><span> -> </span><span>{</span><span>row</span><span>.</span><span>get</span><span>(</span><span>"</span><span>name</span><span>"</span><span>,</span> <span>"</span><span>N/A</span><span>"</span><span>)</span><span>}</span><span>'</span> <span>...</span> <span>}</span> <span># Adding content and metadata to a document object </span><span>docs</span><span>.</span><span>append</span><span>(</span><span>Document</span><span>(</span><span>page_content</span><span>=</span><span>content</span><span>.</span><span>strip</span><span>(),</span> <span>metadata</span><span>=</span><span>metadata</span><span>))</span> <span># Store in database </span><span>vs</span><span>.</span><span>add_documents</span><span>(</span> <span>docs</span><span>,</span> <span>ids</span><span>=</span><span>[</span><span>str</span><span>(</span><span>uuid</span><span>.</span><span>uuid4</span><span>())</span> <span>for</span> <span>_</span> <span>in</span> <span>range</span><span>(</span><span>len</span><span>(</span><span>docs</span><span>))],</span> <span>)</span># Create document content = f"""{row.get('name', 'None')}: {row.get('title_en', 'None')}. {row.get('summary_en', 'None')}""" # Init metadata metadata = { "repository_name": row.get("name", "N/A"), "repository_url": row.get("url", "N/A"), "description": row.get("summary_en", "N/A"), "category_name": row.get("category_name", "N/A"), "language": row.get("primary_lang", "N/A"), "chunk_title": row.get("name", "N/A"), "enhanced_title": f'content -> {row.get("category_name", "N/A")} -> {row.get("name", "N/A")}' ... } # Adding content and metadata to a document object docs.append(Document(page_content=content.strip(), metadata=metadata)) # Store in database vs.add_documents( docs, ids=[str(uuid.uuid4()) for _ in range(len(docs))], )
Enter fullscreen mode Exit fullscreen mode
After several rounds of debugging and tweaking, I discovered that the cleaner and more streamlined the document data, the better the vector retrieval performs. So, I went ahead and stored the complete dataset in thehg5 table in the OceanBase database. This should help us get even more precise results!
python embed_sql.py --table_name hg5 --limit=4000args Namespace(table_name='hg5', batch_size=4, limit=4000, echo=False)Using RemoteOpenAIProcessing: 100%|███████████████████████████████████████████████████████████████████████▉| 3356/3357 [09:33<00:00, 5.85row/s]python embed_sql.py --table_name hg5 --limit=4000 args Namespace(table_name='hg5', batch_size=4, limit=4000, echo=False) Using RemoteOpenAI Processing: 100%|███████████████████████████████████████████████████████████████████████▉| 3356/3357 [09:33<00:00, 5.85row/s]python embed_sql.py --table_name hg5 --limit=4000 args Namespace(table_name='hg5', batch_size=4, limit=4000, echo=False) Using RemoteOpenAI Processing: 100%|███████████████████████████████████████████████████████████████████████▉| 3356/3357 [09:33<00:00, 5.85row/s]
Enter fullscreen mode Exit fullscreen mode

So far, the document data constructed based on the database tables is super clean. Let’s dive into the next part:
4.2 Prompt Word Optimization
After optimizing the data, I turned my attention to how we can enhance the prompt words to better guide and strengthen the responses from the LLM. Here are the key directions for optimizing the prompt words:
- Clear Context and Task: Set the stage by defining the context of the question and narrowing down the scope in the prompt words. This ensures that the questions stay focused on open-source projects or HelloGitHub content.
- Enriched Context: Give the LLM both metadata and the document (project description) so it has more context to generate spot-on responses.
- High-Quality Examples: Provide top-notch response examples with a consistent output format.
- Logical Constraints: Make it crystal clear that the LLM shouldn’t fabricate answers. If it can’t answer a question, it should point out the knowledge gap and offer reasonable suggestions.
4.3 Process Optimization
To fine-tune the vector retrieval and response process, I made these improvements:
- Expanded Retrieval Scope: By default, vector retrieval only returns the top 10 most similar content. I bumped it up to 20 to give the LLM more context options.
- Assessing Relevance: Use prompt words to help the LLM figure out if the question is related to HelloGitHub or open-source projects before generating a response. This avoids irrelevant answers.
- Refined Responses: Based on analyzing what the user is really asking, pick the most relevant 5 projects and craft responses that hit the mark, using metadata to enhance them.
4.4 Showcase of Results
On top of all these optimizations, I streamlined the page and axed any unused code. Here’s the final results:
Comparative effectiveness of responses:
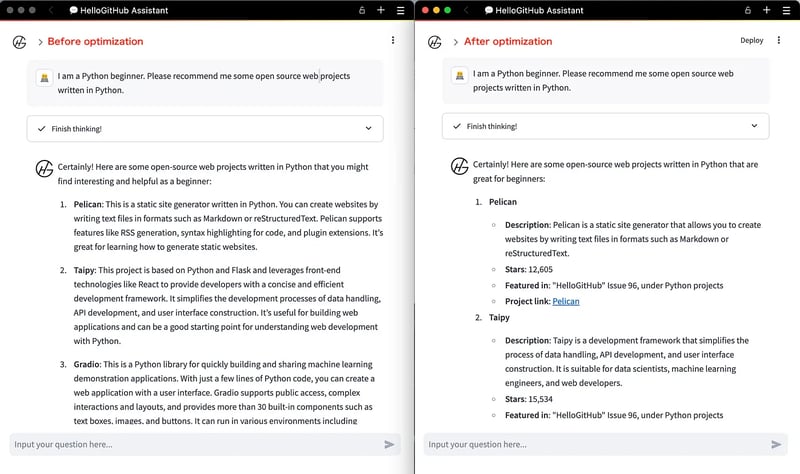
By switching to the Tongyi Qianwen text-embedding-v3 model, optimizing the data, prompt word strategies, and the question-answering process, the response quality of this RAG system has improved significantly. Now I decide to review it once more before deploying it. Meanwhile, I have released the source code for anyone who is interested in using it as a reference:
GitHub: github.com/521xueweihan/ai-workshop-2024
5 Conclusion
Building the RAG chatbot for HelloGitHub was quite the journey. Initially, the response quality was lackluster, and there were moments when I thought about throwing in the towel. But after reconstructing the documents using data from the tables and leveraging a larger-dimensional Embedding model, the responses really started to shape up, reigniting my enthusiasm.
This experience has really got me thinking: What’s the key to optimizing RAG? I’d say it boils down to data + retrieval. These days, loads of businesses are eager to harness AI to supercharge their services, and RAG is a versatile, easy-to-implement solution. Here’s the deal: data quality lays the groundwork, and top-notch data usually comes from sifting through tons of raw info. Retrieval is key to making sure content gets pulled up quickly and accurately. Without it, no matter how much you polish those prompt words, you won’t be able to fetch valuable content or boost the system’s performance.
Looking ahead to future RAG applications, databases need to bring more than just vector data to the table. They’ve got to have some key capabilities to ensure efficient retrieval and generation. For instance, supporting hybrid searches of relational and vector data can handle both structured and unstructured info, and it helps cut down on the “illusion” problem in RAG models. This makes the generated answers more accurate and grounded. Graph search (knowledge graph) is also a big deal because it provides the background info needed for complex reasoning, which ramps up the quality of the generated content.
Plus, in many RAG scenarios, data needs to be updated and synced often, so databases have to support real-time queries, low-latency responses, transaction processing, and high availability. All of these are crucial for keeping RAG running smoothly.
OceanBase’s distributed architecture shines when dealing with massive data. Its new vector storage and retrieval features let us easily get the “cleanest” data through SQL and do vectorization operations all within the same database. The future of OceanBase looks bright!
OceanBase GitHub: github.com/oceanbase/oceanbase
This experience has led me to seriously consider: What is the key to optimizing RAG? My answer is data + retrieval. Nowadays, many businesses are looking to leverage AI technology to empower their existing services, and RAG is a low-threshold general solution. In this process, data quality determines the foundation, and high-quality data often comes from refining massive amounts of data. Retrieval is crucial to ensure that content can be quickly and accurately extracted. Otherwise, no matter how much the prompt words are optimized, valuable content cannot be retrieved, and enhanced effects cannot be achieved.
Furthermore, in future RAG applications, in addition to vector data, databases need to have some key capabilities to ensure efficient retrieval and generation. For example, supporting mixed searches of relational data and vector data can not only handle structured and unstructured data but also effectively reduce the “illusion” problem in RAG models, making the generated answers more accurate and well-founded. Graph search (knowledge graph) is also important, as it provides the background information needed for complex reasoning, thereby improving the quality of generation. In addition, RAG applications in many scenarios require frequent data updates and synchronization, so databases also need to support real-time queries, low-latency responses, transaction processing, and high availability — all of which are the foundation for ensuring the efficient operation of RAG.
The distributed architecture advantage of OceanBase allows it to remain adept in the face of massive data. The newly introduced vector storage and retrieval capabilities enable us to easily obtain the “cleanest” data through SQL and perform vectorization operations within the same database. The future of OceanBase is promising!
GitHub: github.com/oceanbase/oceanbase






暂无评论内容