


Data Analytics often struggle when there is no common column between two datasets, and therefore, there is no way to join 2 tables and aggregate the stats across datasets. However, thanks to LLM, we can now achieve it.
In this short post, I will illustrate how EvaDB enables AI-powered soft/semantic joins between tables that do not directly share a joinable column. The remarkable part is that this can be done without leaving your favorite database, whether it’s PostgreSQL, MySQL, etc.
Challenge: “AI-Powered” Join
Consider a scenario where you have two tables - one with details about AirBnB listings in San Francisco and the other providing insights into the city’s parks. Our objective is to identify Airbnb listings located in neighborhoods with a high concentration of nearby parks. These tables/datasets lack a common column for a straightforward join. The Airbnb dataset includes a neighborhood column, while the parks dataset features a zipcode column.
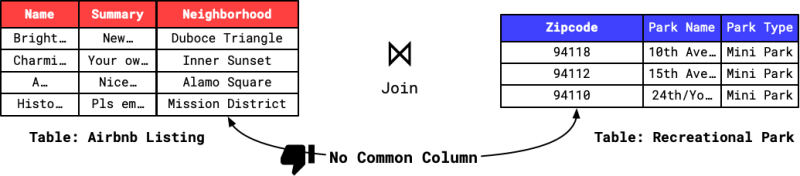
EvaDB addresses this challenge by facilitating the merging operation using LLMs. Below is the key query to create a new reference table that can be joined with other tables easily.
CREATE TABLE reference_table AS
SELECT parkname, parktype,
LLM(
"Return the San Francisco neighborhood name when provided with a zipcode. The possible neighborhoods are: {neighbourhoods_str}. The response should be an item from the provided list. Do not add any more words.",
zipcode)
FROM postgres_db.recreational_park_dataset;
Enter fullscreen mode Exit fullscreen mode
As depicted in the figure below, it generates a new table with the neighborhood column corresponding to the zipcode, enabling us to seamlessly join the two datasets using the neighborhood column.
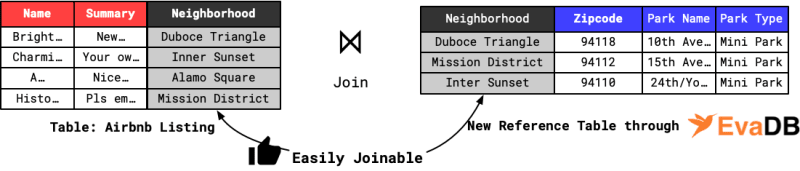
How cool is this? 🤩 Mind-blown!
- Full Tutorial: Google Colab.
- Show some ️️ to EvaDB! Your support motivates me to keep the project going. 🤝























暂无评论内容