


Para o post de hoje resolvi trazer um projeto de análise de dados utilizando os dados do Airbnb - Rio de Janeiro. Nesse post, quero mostrar um pouco como é feita uma análise de dados. Espero que goste 🙂
Claro que como boa carioca escolhi os dados do meu RJ rs

Se você ainda não conhece o Airbnb, saiba que essa empresa só vem ganhando o coração dos viajantes, mas caso você não conheça trago uma breve explicação do que o Airbnb oferece.
Airbnb é um serviço online comunitário para as pessoas anunciarem, descobrirem e reservarem acomodações e meios de hospedagem.
O Airbnb permite aos indivíduos alugar todo ou parte de sua própria casa, assim os anfitriões conseguem transformar um cômodo extra ou uma casa extra em uma graninha. O site fornece uma plataforma de busca e reservas entre a pessoa que oferece a acomodação e a pessoa que busca pela locação.
Vamos para as análises?

Vamos começar pelo nosso clássico import de bibliotecas, aqui como vamos fazer apenas uma análise, acaba que não temos muitas bibliotecas para importar, mas espera só vir posts de projetos de Machine Learning para vocês verem o quão cheia essa célula vai ficar rs
!pip install missingno# importar os pacotes necessários%matplotlib inlineimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport missingno as msno# configurar as visualizaçõessns.set_style('darkgrid')sns.set_palette('Accent')!pip install missingno # importar os pacotes necessários %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import missingno as msno # configurar as visualizações sns.set_style('darkgrid') sns.set_palette('Accent')!pip install missingno # importar os pacotes necessários %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import missingno as msno # configurar as visualizações sns.set_style('darkgrid') sns.set_palette('Accent')
Enter fullscreen mode Exit fullscreen mode
Ali em cima também fiz o !pip de uma biblioteca que iremos utilizar para visualizar, através de um gráfico, as colunas com dados faltantes do nosso dataset.
O próximo passo é carregador os nossos dados para dentro de um DataFrame.
Como temos um arquivo csv, vamos utilizar o pd.read_csv, como mostro abaixo:
# obtendo os dadosdata_path = 'http://data.insideairbnb.com/brazil/rj/rio-de-janeiro/2020-04-20/visualisations/listings.csv'df = pd.read_csv(data_path)df.head()# obtendo os dados data_path = 'http://data.insideairbnb.com/brazil/rj/rio-de-janeiro/2020-04-20/visualisations/listings.csv' df = pd.read_csv(data_path) df.head()# obtendo os dados data_path = 'http://data.insideairbnb.com/brazil/rj/rio-de-janeiro/2020-04-20/visualisations/listings.csv' df = pd.read_csv(data_path) df.head()
Enter fullscreen mode Exit fullscreen mode
Além disso, como a função .head() conseguimos mostras as 5 primeiras linhas do nosso DataFrame. Caso você queira mostrar mais que 5 linhas, basta colocar a quantidade de linhas dentro dos parênteses 🙂 O default da função é mostrar apenas 5 linhas.

Algo que gosto de acrescentar nos projetos é o Dicionário de Variáveis. Ele nos diz o que é cada variável. Isso é ótimo para conhecermos melhor os nossos dados e com certeza vai nos ajudar nas análises.
Análise Exploratória de Dados
Nesse projeto eu fiz uma série de perguntas e fui respondendo com os códigos. Na época, eu estava iniciando os estudos e fazer isso me ajudou bastante a entender um pouco como uma análise deve ser feito, quais respostas eu devo trazer ao projeto.
Quantos atributos/variáveis/colunas e quantas entradas/linhas possui o nosso dataframe?
print('DIMENSÕES DO DATAFRAME:')print(f'Linhas: {df.shape[0]}')print(f'Colunas: {df.shape[1]}')print('DIMENSÕES DO DATAFRAME:') print(f'Linhas: {df.shape[0]}') print(f'Colunas: {df.shape[1]}')print('DIMENSÕES DO DATAFRAME:') print(f'Linhas: {df.shape[0]}') print(f'Colunas: {df.shape[1]}')
Enter fullscreen mode Exit fullscreen mode
O .shape nos retorna uma tupla representando a dimensionalidade do DataFrame. (linhas, colunas)
Para acessar o primeiro elemento dessa tupla eu utilizei o [0] e para acessar o segundo elemento utilizei o [1] junto do .shape

Quais são os tipos de dados (dtypes) das nossas variáveis?
df.dtypesdf.dtypes.value_counts()df.dtypes df.dtypes.value_counts()df.dtypes df.dtypes.value_counts()
Enter fullscreen mode Exit fullscreen mode
A propriedade .dtypes retorna uma série com o tipos de dado de cada coluna.

Se você quiser saber quantas colunas de cada tipo de dados esse dataframe possui e não quer ficar contando na mão, utilize o método .value_counts()

Nosso dataset possui valores ausentes?
df.isna().any()df.isna().sum()# visualização das entradas de cada colunamsno.bar (df, figsize = (10,5));#eliminando a colunaneighbourhood_groupdf.drop('neighbourhood_group', axis=1, inplace=True)df.isna().any() df.isna().sum() # visualização das entradas de cada coluna msno.bar (df, figsize = (10,5)); #eliminando a colunaneighbourhood_group df.drop('neighbourhood_group', axis=1, inplace=True)df.isna().any() df.isna().sum() # visualização das entradas de cada coluna msno.bar (df, figsize = (10,5)); #eliminando a colunaneighbourhood_group df.drop('neighbourhood_group', axis=1, inplace=True)
Enter fullscreen mode Exit fullscreen mode
Para “perguntar” ao dataframe se existe alguma coluna com valor NaN, utilizamos o .isna().any(). Ele irá retornar True ou False para cada coluna.

E para saber quantos valores ausentes cada coluna possui, utilizamos .isna().sum()

Lembra da biblioteca missingno que importamos? Então, ela nos traz mais uma forma de visualizar os dados faltantes de cada coluna.
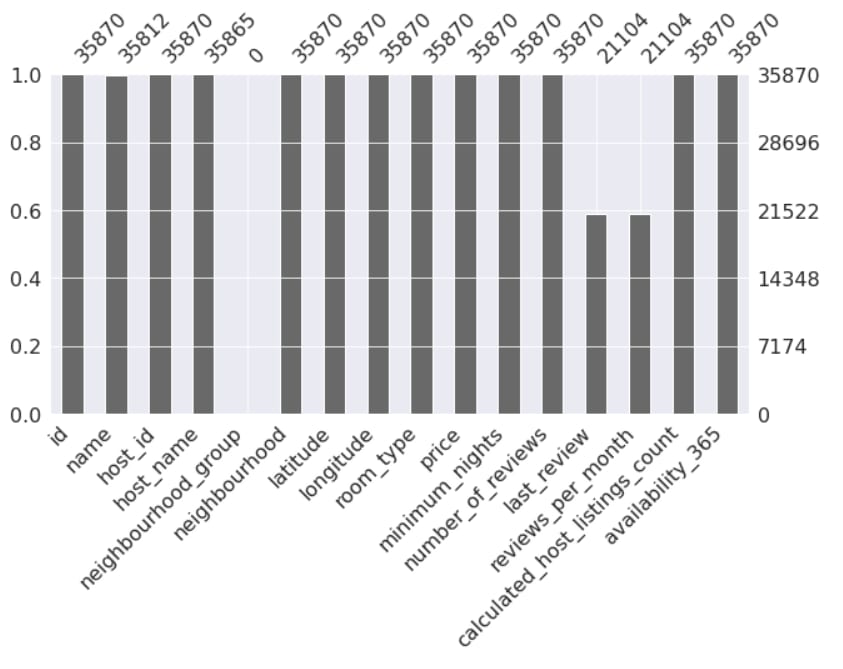
Como vimos anteriormente, nosso dataset possui 35.870 entradas. E analisando os valores ausentes no comando anterior notamos que a variável neighbourhood_group não tem dados. Sendo assim, ela não acrescentará em nada na nossa análise, com o .drop() eliminei essa variável do DataFrame.
Histograma das Variáveis
Você sabe o que é um histograma?
O histograma, também é conhecido como distribuição de frequências, é a representação gráfica em colunas ou em barras de um conjunto de dados. Se você quer entender melhor sobre, clique aqui.
# análise visual das variáveis númericas através de um gráfico de frequências (histogramas)df.hist(bins=15, figsize=(15,10));# análise visual das variáveis númericas através de um gráfico de frequências (histogramas) df.hist(bins=15, figsize=(15,10));# análise visual das variáveis númericas através de um gráfico de frequências (histogramas) df.hist(bins=15, figsize=(15,10));
Enter fullscreen mode Exit fullscreen mode

Notamos que há índicios da presença de outliers nos nossos dados, como vemos nas colunas price, minimum_nights e calculated_host_listings_count. Um dos indícios é o fato de não conseguirmos visualizar uma distribuição porque possivelmente os outliers, se presentes, estão distorcento a representação gráfica.
Detecção de Outliers
# visualizando um resumo estatístico das variáveis númericasdf[['price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month', 'calculated_host_listings_count', 'availability_365']].describe().round(2)# visualizando um resumo estatístico das variáveis númericas df[['price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month', 'calculated_host_listings_count', 'availability_365']].describe().round(2)# visualizando um resumo estatístico das variáveis númericas df[['price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month', 'calculated_host_listings_count', 'availability_365']].describe().round(2)
Enter fullscreen mode Exit fullscreen mode
Esse método traz muitas informaçãoes relevantes para a análise exploratória. Como média das colunas, o valor mínimo e máximo, seus quartis e também o valor do desvio padrão. Muitas vezes conseguimos visualizar possíveis outliers por aqui.

Pontos principais da análise feita através do método describe:
- O valor mínimo da variável price é 0
- O valor máximo da variável price é 131.727
- O valor máximo da variável minimum_nights é 1.123
- O valor máximo da variável calculated_host_listinings_count é 200
Boxplot das variáveis que possivelmente apresentam outliers
Em estatística descritiva, diagrama de caixa, diagrama de extremos e quartis, boxplot ou box plot é uma ferramenta gráfica para representar a variação de dados observados de uma variável numérica por meio de quartis. Wikipédia
Boxplot da variável minimum_nights
plt.figure(figsize=(15,3))sns.boxplot(data=df, x='minimum_nights')plt.title('Boxplot minimum_nights')plt.show()# ver quantidade de valores acima de 30 dias para minimum_nightsprint(f'[minimun_nights]\nValores acima de 30:{len(df[df.minimum_nights > 30])} entradas')print('Porcentagem: {:.4f}%'.format(len(df[df.minimum_nights > 30])/ len(df.minimum_nights)* 100))plt.figure(figsize=(15,3)) sns.boxplot(data=df, x='minimum_nights') plt.title('Boxplot minimum_nights') plt.show() # ver quantidade de valores acima de 30 dias para minimum_nights print(f'[minimun_nights]\nValores acima de 30:{len(df[df.minimum_nights > 30])} entradas') print('Porcentagem: {:.4f}%'.format(len(df[df.minimum_nights > 30])/ len(df.minimum_nights)* 100))plt.figure(figsize=(15,3)) sns.boxplot(data=df, x='minimum_nights') plt.title('Boxplot minimum_nights') plt.show() # ver quantidade de valores acima de 30 dias para minimum_nights print(f'[minimun_nights]\nValores acima de 30:{len(df[df.minimum_nights > 30])} entradas') print('Porcentagem: {:.4f}%'.format(len(df[df.minimum_nights > 30])/ len(df.minimum_nights)* 100))
Enter fullscreen mode Exit fullscreen mode
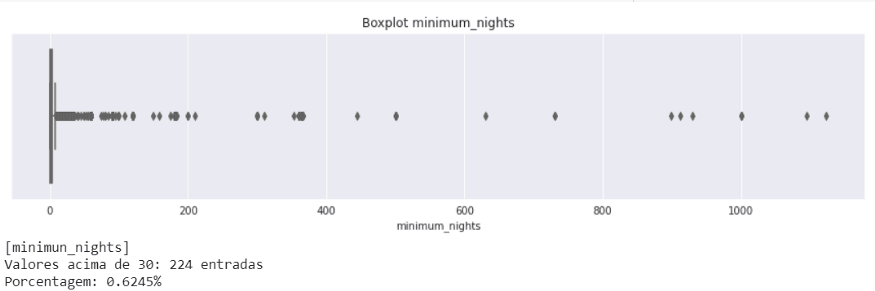
Temos 224 entradas com minimum_nights acima de 30, o que corresponde a 0.62% dos dados.
Boxplot da variável Price
plt.figure(figsize=(15,3))sns.boxplot(data=df, x='price')plt.title('Boxplot price')plt.show()# ver quantidade de valores acima de 1500 para priceprint(f'[price]\nValores acima de 1500: {len(df[df.price > 1500])} entradas')print('Porcentagem: {:.4f}%'.format(len(df[df.price > 1500])/ len(df.price) * 100)plt.figure(figsize=(15,3)) sns.boxplot(data=df, x='price') plt.title('Boxplot price') plt.show() # ver quantidade de valores acima de 1500 para price print(f'[price]\nValores acima de 1500: {len(df[df.price > 1500])} entradas') print('Porcentagem: {:.4f}%'.format(len(df[df.price > 1500])/ len(df.price) * 100)plt.figure(figsize=(15,3)) sns.boxplot(data=df, x='price') plt.title('Boxplot price') plt.show() # ver quantidade de valores acima de 1500 para price print(f'[price]\nValores acima de 1500: {len(df[df.price > 1500])} entradas') print('Porcentagem: {:.4f}%'.format(len(df[df.price > 1500])/ len(df.price) * 100)
Enter fullscreen mode Exit fullscreen mode

Temos 3.360 entradas com Price acima de 1.500, o que corresponde a 9.36% dos dados.
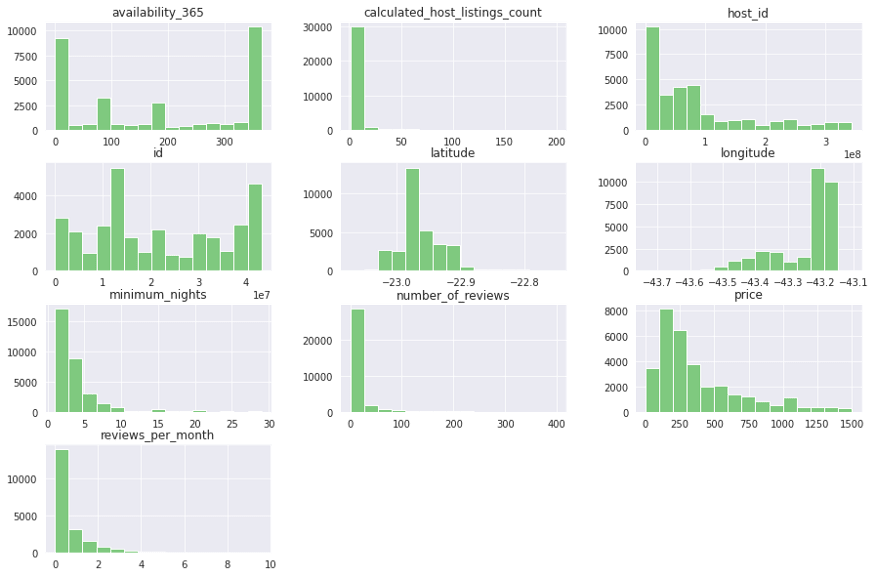
Histograma sem Outlier
Depois de identificar os outliers, vamos plotar novamente o histograma para visualizarmos os dados limpos.
# histogramas com valores de minimum_nights menor que 30 e price menor que 1500df_clean = df.copy()df_clean = df_clean.query('minimum_nights < 30 & price < 1500')df_clean.hist(bins=15, figsize=(15,10));# histogramas com valores de minimum_nights menor que 30 e price menor que 1500 df_clean = df.copy() df_clean = df_clean.query('minimum_nights < 30 & price < 1500') df_clean.hist(bins=15, figsize=(15,10));# histogramas com valores de minimum_nights menor que 30 e price menor que 1500 df_clean = df.copy() df_clean = df_clean.query('minimum_nights < 30 & price < 1500') df_clean.hist(bins=15, figsize=(15,10));
Enter fullscreen mode Exit fullscreen mode
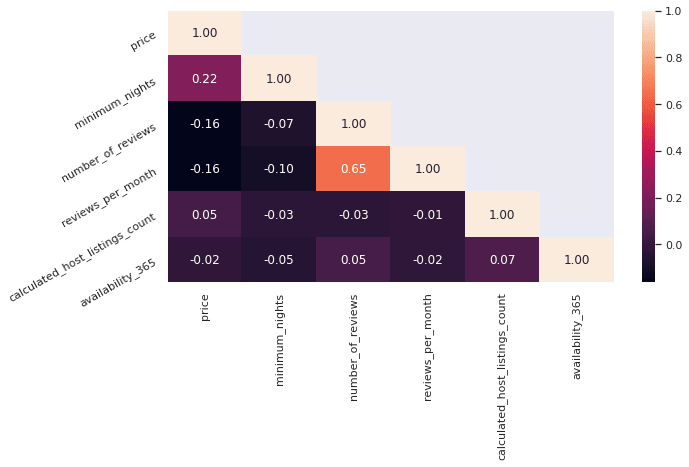
Correlação existente entre as variáveis
Correlação é a relação estatística entre duas variáveis. Os coeficientes de correlação são métodos estatísticos para se medir as relações entre variáveis.
Calculamos o coeficiente de correlação com a função .corr()
Irei apresentar essa correlação através de uma matriz e de uma forma mais visual através de um heatmap (mapa de calor).
corr = df_clean[['price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month','calculated_host_listings_count', 'availability_365']].corr()#plotando a matriz de correlaçãosns.set_context("notebook", font_scale=1.0, rc={"lines.linewidth": 2.5})plt.figure(figsize=(10,5))#criando uma máscara para ver apenas os valores de correlação uma vezmask = np.zeros_like(corr)mask[np.triu_indices_from(mask, 1)] = Truea = sns.heatmap(corr, mask=mask, annot=True, fmt='.2f')rotx = a.set_xticklabels(a.get_xticklabels(), rotation=90)roty = a.set_yticklabels(a.get_yticklabels(), rotation=30)corr = df_clean[['price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month', 'calculated_host_listings_count', 'availability_365']].corr() #plotando a matriz de correlação sns.set_context("notebook", font_scale=1.0, rc={"lines.linewidth": 2.5}) plt.figure(figsize=(10,5)) #criando uma máscara para ver apenas os valores de correlação uma vez mask = np.zeros_like(corr) mask[np.triu_indices_from(mask, 1)] = True a = sns.heatmap(corr, mask=mask, annot=True, fmt='.2f') rotx = a.set_xticklabels(a.get_xticklabels(), rotation=90) roty = a.set_yticklabels(a.get_yticklabels(), rotation=30)corr = df_clean[['price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month', 'calculated_host_listings_count', 'availability_365']].corr() #plotando a matriz de correlação sns.set_context("notebook", font_scale=1.0, rc={"lines.linewidth": 2.5}) plt.figure(figsize=(10,5)) #criando uma máscara para ver apenas os valores de correlação uma vez mask = np.zeros_like(corr) mask[np.triu_indices_from(mask, 1)] = True a = sns.heatmap(corr, mask=mask, annot=True, fmt='.2f') rotx = a.set_xticklabels(a.get_xticklabels(), rotation=90) roty = a.set_yticklabels(a.get_yticklabels(), rotation=30)
Enter fullscreen mode Exit fullscreen mode
Qual é o tipo de hospedagem mais alugado?
# a quantidade de cada tipo de imóvel disponíveldf_clean['room_type'].value_counts()# porcentagem de cada tipo de imóvel disponíveldf_clean['room_type'].value_counts() / len(df_clean)# a quantidade de cada tipo de imóvel disponível df_clean['room_type'].value_counts() # porcentagem de cada tipo de imóvel disponível df_clean['room_type'].value_counts() / len(df_clean)# a quantidade de cada tipo de imóvel disponível df_clean['room_type'].value_counts() # porcentagem de cada tipo de imóvel disponível df_clean['room_type'].value_counts() / len(df_clean)
Enter fullscreen mode Exit fullscreen mode

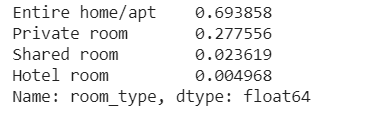
Qual é a localidade mais cara?
# média de preço do top 10 localidades mais carasdf_clean.groupby('neighbourhood')['price'].mean().sort_values(ascending=False)[:10]# contagem de imóveis por localidadedf_clean['neighbourhood'].value_counts()# média de preço do top 10 localidades mais caras df_clean.groupby('neighbourhood')['price'].mean().sort_values(ascending=False)[:10] # contagem de imóveis por localidade df_clean['neighbourhood'].value_counts()# média de preço do top 10 localidades mais caras df_clean.groupby('neighbourhood')['price'].mean().sort_values(ascending=False)[:10] # contagem de imóveis por localidade df_clean['neighbourhood'].value_counts()
Enter fullscreen mode Exit fullscreen mode

Observação: Como podemos ver existem bairros com mais imóveis alugados, o que pode influenciar diretamente na média de preços por localidade.

Plotando os imóveis pela latitude-longitude
df_clean.plot(kind='scatter', x='longitude', y='latitude',alpha=0.4, c=df_clean['price'], s=8, cmap=plt.get_cmap('jet'),figsize=(12,8));df_clean.plot(kind='scatter', x='longitude', y='latitude', alpha=0.4, c=df_clean['price'], s=8, cmap=plt.get_cmap('jet'), figsize=(12,8));df_clean.plot(kind='scatter', x='longitude', y='latitude', alpha=0.4, c=df_clean['price'], s=8, cmap=plt.get_cmap('jet'), figsize=(12,8));
Enter fullscreen mode Exit fullscreen mode

Conclusões:
-
Aqui foi feita uma análise superficial sobre os dados disponíveis no arquivo citado anteriormente. Para uma análise mais completa recomendo que seja utilizado o dataset que contém mais variáveis/atributos.
-
Conseguimos identificar valores ausentes e outliers, fazer seu tratamento, plotamos alguns gráficos para análise e no final conseguimos responder algumas perguntas.
-
Link do projeto no GitHub: https://bit.ly/3fHgAzX
-
Link do projeto no Google Colab: https://bit.ly/3hQ18Da
Contatos:
- [LinkedIn]: https://www.linkedin.com/in/beatrizmaiads/
- [GitHub]: https://github.com/beatrizmaiads
- [Instagram]: @beatrizmaiads
- [Dev.to]: https://dev.to/beatrizmaiads
- [Medium]: https://medium.com/@beatrizmaiads
- [E-mail]: beatrizmaiads@outlook.com





暂无评论内容