


EDIT: After both nights of the debate concluded I did a more thorough write up. I’d encourage you to check that out.
![图片[1]-Primary Debate Analysis Quickstart - 拾光赋-拾光赋](https://res.cloudinary.com/practicaldev/image/fetch/s--lCADa4Oh--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://res.cloudinary.com/practicaldev/image/fetch/s--Mq_ZF544--/c_fill%2Cf_auto%2Cfl_progressive%2Ch_150%2Cq_auto%2Cw_150/https://dev-to-uploads.s3.amazonaws.com/uploads/user/profile_image/127580/382ebda2-b188-47ef-bde0-dea8428efcb5.jpg)
Visualizing the Primary Debates
Charles Landau ・ Aug 1 ’19 ・ 1 min read
#dataviz #showdev #python #nlp
If you’re watching the debate tonight and thought “how can I analyze the transcript data from this?” Here’s some starter code to parse the transcript simply and easily.
<span>import</span> <span>pandas</span> <span>as</span> <span>pd</span><span>import</span> <span>sklearn</span> <span>as</span> <span>sk</span><span>import</span> <span>requests</span><span>import</span> <span>bs4</span><span># http request </span><span>r</span> <span>=</span> <span>requests</span><span>.</span><span>get</span><span>(</span><span>'https://www.washingtonpost.com/politics/'</span><span>'2019/07/31/transcript-first-night-second-democratic-debate'</span><span>)</span><span>r</span><span>.</span><span>status_code</span><span># Parse html </span><span>soup</span> <span>=</span> <span>bs4</span><span>.</span><span>BeautifulSoup</span><span>(</span><span>r</span><span>.</span><span>content</span><span>)</span><span>graphs</span> <span>=</span> <span>soup</span><span>.</span><span>find_all</span><span>(</span><span>'p'</span><span>)</span><span>utterances</span> <span>=</span> <span>[</span><span>x</span><span>.</span><span>get_text</span><span>()</span> <span>for</span> <span>x</span> <span>in</span> <span>graphs</span> <span>if</span> <span>'data-elm-loc'</span> <span>in</span> <span>x</span><span>.</span><span>attrs</span><span>.</span><span>keys</span><span>()]</span><span># Parse utterances </span><span>utterances</span> <span>=</span> <span>utterances</span> <span>[</span><span>2</span><span>:]</span><span>seq</span> <span>=</span> <span>0</span><span>data</span> <span>=</span> <span>[]</span><span>for</span> <span>i</span> <span>in</span> <span>utterances</span><span>:</span><span>graph</span> <span>=</span> <span>i</span><span>.</span><span>split</span><span>()</span><span>if</span> <span>graph</span><span>[</span><span>0</span><span>][</span><span>-</span><span>1</span><span>]</span> <span>==</span> <span>':'</span><span>:</span><span>text</span> <span>=</span> <span>' '</span><span>.</span><span>join</span><span>(</span><span>graph</span><span>[</span><span>1</span><span>:])</span><span>num_words</span> <span>=</span> <span>len</span><span>(</span><span>graph</span><span>)</span> <span>-</span> <span>1</span><span>name</span> <span>=</span> <span>graph</span><span>[</span><span>0</span><span>][:</span><span>-</span><span>1</span><span>]</span><span>seq</span> <span>+=</span> <span>1</span><span>elif</span> <span>len</span><span>(</span><span>graph</span><span>)</span> <span>></span> <span>1</span> <span>and</span> <span>graph</span><span>[</span><span>1</span><span>]</span> <span>==</span> <span>'(?):'</span><span>:</span><span># Cases like 'WARREN (?):' </span> <span>text</span> <span>=</span> <span>' '</span><span>.</span><span>join</span><span>(</span><span>graph</span><span>[</span><span>2</span><span>:])</span><span>num_words</span> <span>=</span> <span>len</span><span>(</span><span>graph</span><span>)</span> <span>-</span> <span>2</span><span>name</span> <span>=</span> <span>graph</span><span>[</span><span>0</span><span>]</span><span>seq</span> <span>+=</span> <span>1</span><span>else</span><span>:</span><span>text</span> <span>=</span> <span>' '</span><span>.</span><span>join</span><span>(</span><span>graph</span><span>)</span><span>data</span><span>.</span><span>append</span><span>({</span><span>"name"</span><span>:</span> <span>name</span><span>,</span><span>"graph"</span><span>:</span> <span>text</span><span>,</span><span>"seq"</span><span>:</span> <span>seq</span><span>,</span><span>"num_words"</span><span>:</span> <span>num_words</span><span>})</span><span>df</span> <span>=</span> <span>pd</span><span>.</span><span>DataFrame</span><span>(</span><span>data</span><span>)</span><span># "Unknown", O'Rourke parsing errors </span><span>df</span> <span>=</span> <span>df</span><span>[</span><span>df</span><span>.</span><span>name</span> <span>!=</span> <span>"(UNKNOWN)"</span><span>]</span><span>df</span><span>[</span><span>'name'</span><span>]</span> <span>=</span> <span>df</span><span>[</span><span>'name'</span><span>].</span><span>apply</span><span>(</span><span>lambda</span> <span>x</span><span>:</span> <span>''</span><span>.</span><span>join</span><span>([</span><span>char</span> <span>for</span> <span>char</span> <span>in</span> <span>x</span> <span>if</span> <span>char</span><span>.</span><span>isalpha</span><span>()]))</span><span># Example... </span><span>df</span><span>.</span><span>groupby</span><span>(</span><span>'name'</span><span>).</span><span>sum</span><span>()[</span><span>'num_words'</span><span>].</span><span>plot</span><span>(</span><span>kind</span><span>=</span><span>'bar'</span><span>)</span><span>import</span> <span>pandas</span> <span>as</span> <span>pd</span> <span>import</span> <span>sklearn</span> <span>as</span> <span>sk</span> <span>import</span> <span>requests</span> <span>import</span> <span>bs4</span> <span># http request </span><span>r</span> <span>=</span> <span>requests</span><span>.</span><span>get</span><span>(</span><span>'https://www.washingtonpost.com/politics/'</span> <span>'2019/07/31/transcript-first-night-second-democratic-debate'</span><span>)</span> <span>r</span><span>.</span><span>status_code</span> <span># Parse html </span><span>soup</span> <span>=</span> <span>bs4</span><span>.</span><span>BeautifulSoup</span><span>(</span><span>r</span><span>.</span><span>content</span><span>)</span> <span>graphs</span> <span>=</span> <span>soup</span><span>.</span><span>find_all</span><span>(</span><span>'p'</span><span>)</span> <span>utterances</span> <span>=</span> <span>[</span><span>x</span><span>.</span><span>get_text</span><span>()</span> <span>for</span> <span>x</span> <span>in</span> <span>graphs</span> <span>if</span> <span>'data-elm-loc'</span> <span>in</span> <span>x</span><span>.</span><span>attrs</span><span>.</span><span>keys</span><span>()]</span> <span># Parse utterances </span><span>utterances</span> <span>=</span> <span>utterances</span> <span>[</span><span>2</span><span>:]</span> <span>seq</span> <span>=</span> <span>0</span> <span>data</span> <span>=</span> <span>[]</span> <span>for</span> <span>i</span> <span>in</span> <span>utterances</span><span>:</span> <span>graph</span> <span>=</span> <span>i</span><span>.</span><span>split</span><span>()</span> <span>if</span> <span>graph</span><span>[</span><span>0</span><span>][</span><span>-</span><span>1</span><span>]</span> <span>==</span> <span>':'</span><span>:</span> <span>text</span> <span>=</span> <span>' '</span><span>.</span><span>join</span><span>(</span><span>graph</span><span>[</span><span>1</span><span>:])</span> <span>num_words</span> <span>=</span> <span>len</span><span>(</span><span>graph</span><span>)</span> <span>-</span> <span>1</span> <span>name</span> <span>=</span> <span>graph</span><span>[</span><span>0</span><span>][:</span><span>-</span><span>1</span><span>]</span> <span>seq</span> <span>+=</span> <span>1</span> <span>elif</span> <span>len</span><span>(</span><span>graph</span><span>)</span> <span>></span> <span>1</span> <span>and</span> <span>graph</span><span>[</span><span>1</span><span>]</span> <span>==</span> <span>'(?):'</span><span>:</span> <span># Cases like 'WARREN (?):' </span> <span>text</span> <span>=</span> <span>' '</span><span>.</span><span>join</span><span>(</span><span>graph</span><span>[</span><span>2</span><span>:])</span> <span>num_words</span> <span>=</span> <span>len</span><span>(</span><span>graph</span><span>)</span> <span>-</span> <span>2</span> <span>name</span> <span>=</span> <span>graph</span><span>[</span><span>0</span><span>]</span> <span>seq</span> <span>+=</span> <span>1</span> <span>else</span><span>:</span> <span>text</span> <span>=</span> <span>' '</span><span>.</span><span>join</span><span>(</span><span>graph</span><span>)</span> <span>data</span><span>.</span><span>append</span><span>({</span><span>"name"</span><span>:</span> <span>name</span><span>,</span> <span>"graph"</span><span>:</span> <span>text</span><span>,</span> <span>"seq"</span><span>:</span> <span>seq</span><span>,</span> <span>"num_words"</span><span>:</span> <span>num_words</span><span>})</span> <span>df</span> <span>=</span> <span>pd</span><span>.</span><span>DataFrame</span><span>(</span><span>data</span><span>)</span> <span># "Unknown", O'Rourke parsing errors </span><span>df</span> <span>=</span> <span>df</span><span>[</span><span>df</span><span>.</span><span>name</span> <span>!=</span> <span>"(UNKNOWN)"</span><span>]</span> <span>df</span><span>[</span><span>'name'</span><span>]</span> <span>=</span> <span>df</span><span>[</span><span>'name'</span><span>].</span><span>apply</span><span>(</span><span>lambda</span> <span>x</span><span>:</span> <span>''</span><span>.</span><span>join</span><span>([</span><span>char</span> <span>for</span> <span>char</span> <span>in</span> <span>x</span> <span>if</span> <span>char</span><span>.</span><span>isalpha</span><span>()]))</span> <span># Example... </span><span>df</span><span>.</span><span>groupby</span><span>(</span><span>'name'</span><span>).</span><span>sum</span><span>()[</span><span>'num_words'</span><span>].</span><span>plot</span><span>(</span><span>kind</span><span>=</span><span>'bar'</span><span>)</span>import pandas as pd import sklearn as sk import requests import bs4 # http request r = requests.get('https://www.washingtonpost.com/politics/' '2019/07/31/transcript-first-night-second-democratic-debate') r.status_code # Parse html soup = bs4.BeautifulSoup(r.content) graphs = soup.find_all('p') utterances = [x.get_text() for x in graphs if 'data-elm-loc' in x.attrs.keys()] # Parse utterances utterances = utterances [2:] seq = 0 data = [] for i in utterances: graph = i.split() if graph[0][-1] == ':': text = ' '.join(graph[1:]) num_words = len(graph) - 1 name = graph[0][:-1] seq += 1 elif len(graph) > 1 and graph[1] == '(?):': # Cases like 'WARREN (?):' text = ' '.join(graph[2:]) num_words = len(graph) - 2 name = graph[0] seq += 1 else: text = ' '.join(graph) data.append({"name": name, "graph": text, "seq": seq, "num_words": num_words}) df = pd.DataFrame(data) # "Unknown", O'Rourke parsing errors df = df[df.name != "(UNKNOWN)"] df['name'] = df['name'].apply(lambda x: ''.join([char for char in x if char.isalpha()])) # Example... df.groupby('name').sum()['num_words'].plot(kind='bar')
Enter fullscreen mode Exit fullscreen mode
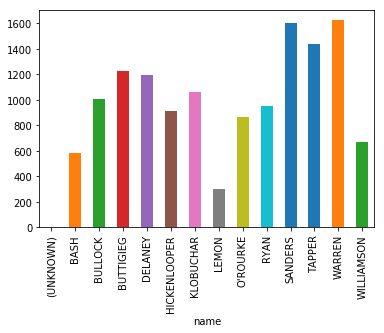
(Image taken mid-debate, those are not final numbers)
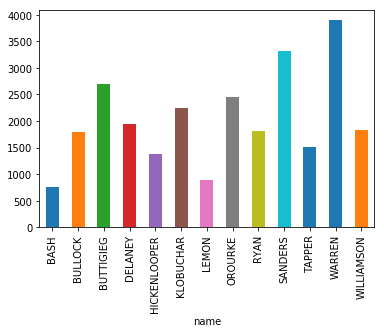
(Cleaned, post-debate numbers)
You can quickly get started with this code and more in an interactive notebook on Kaggle:
https://www.kaggle.com/charleslandau/democratic-debate-analysis-quickstart
© 版权声明
THE END






























暂无评论内容